





What Is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation, commonly called RAG, is an AI architecture that combines information retrieval with generative AI. Instead of relying only on what an AI model learned during training, a RAG system searches external knowledge sources and uses that information to generate more accurate and relevant responses.
Think of it like an open-book exam.
A traditional AI model answers questions using information stored in its training data. A RAG system can first look up relevant documents, articles, databases, or company knowledge bases and then use that information to build its answer.
This approach helps AI provide responses that are more current, contextual, and trustworthy.
Excerpt: RAG is an AI approach that retrieves relevant information from external sources before generating a response.
Why Was RAG Created?
Large language models are impressive, but they have limitations.
They don’t automatically know what happened yesterday.
They may not have access to company-specific knowledge.
They can occasionally generate information that sounds convincing but isn’t accurate.
This created a challenge.
Organizations wanted AI systems that could answer questions using their own documents, policies, manuals, and databases.
RAG emerged as a solution.
Instead of retraining a massive AI model every time information changes, a RAG system retrieves fresh information whenever a question is asked.
The model stays smart, and the knowledge stays current.
Let’s Make It Simple
Imagine you ask an AI assistant:
“What is our company’s refund policy?”
A traditional AI model may not know.
A RAG-powered assistant works differently.
It first searches the company’s documentation, finds the latest refund policy, and then generates a response based on that document.
The answer becomes grounded in actual company information rather than guesswork.
That’s the core idea behind RAG.
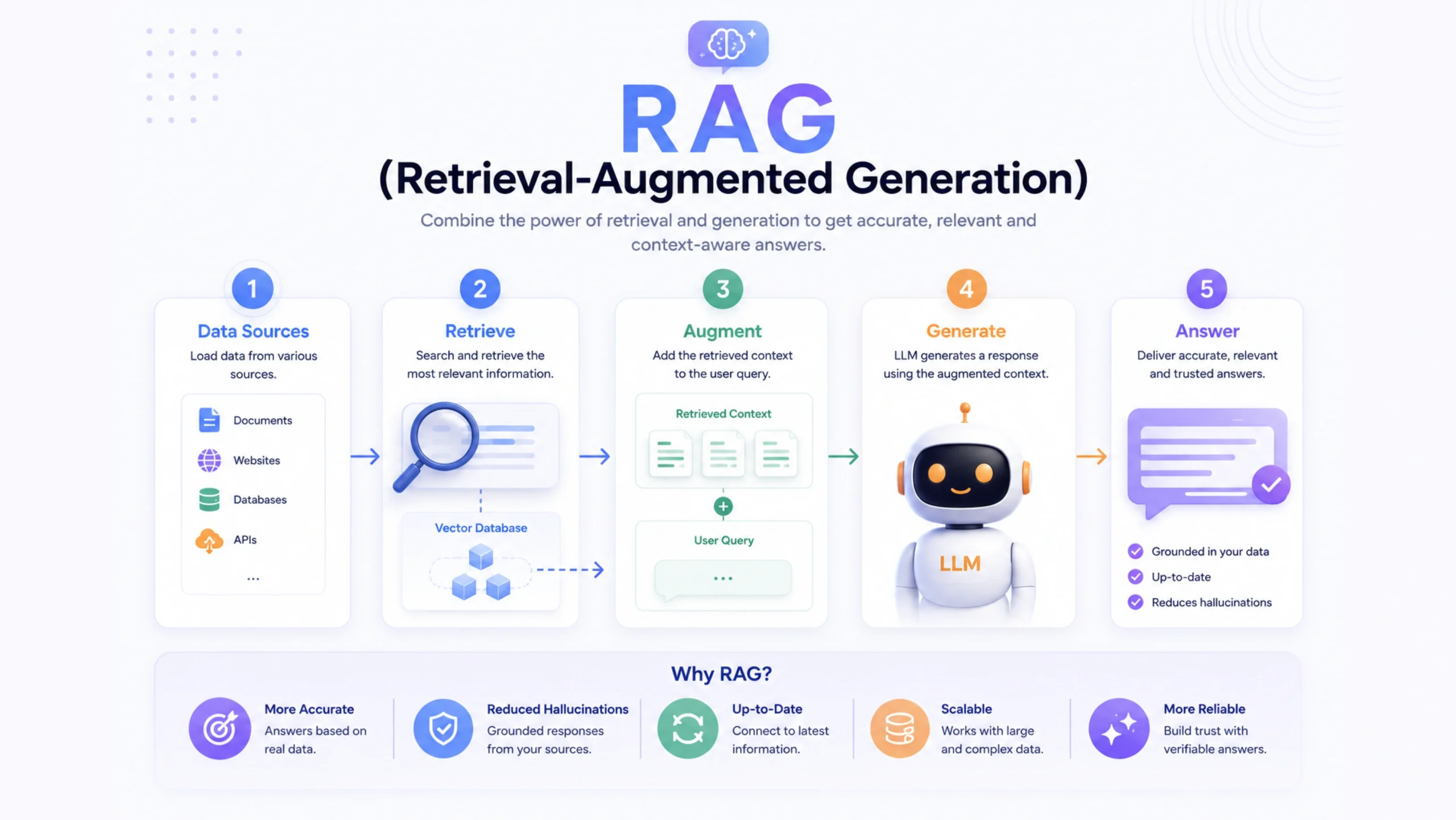
How RAG Works
Although RAG sounds technical, the process is surprisingly straightforward.
Step 1: User Submits a Question
A user enters a query.
For example:
“What are the eligibility requirements for employee health benefits?”
The system receives the request and prepares to search for relevant information.
Step 2: Information Retrieval
The retrieval engine searches connected knowledge sources.
These sources may include:
- Internal documents
- PDFs
- Knowledge bases
- Databases
- Wikis
- Websites
- Research papers
The system identifies content related to the user’s question.
Step 3: Relevant Content Is Selected
The retrieval system ranks and selects the most useful pieces of information.
Instead of searching an entire library, it focuses on the sections most likely to answer the question.
This keeps responses focused and efficient.
Step 4: Context Is Sent to the AI Model
The retrieved information is added to the prompt sent to the language model.
The AI receives:
- The user’s question
- Supporting documents
- Additional context
This gives the model a reliable source of information to reference.
Step 5: Response Generation
The language model generates a natural-language response using both the user’s question and the retrieved content.
The result feels conversational while remaining grounded in actual information.
The Core Components of a RAG System
A typical RAG system contains several major parts.
Knowledge Source
This is where information is stored.
Examples include:
- Company documentation
- Product manuals
- Research libraries
- Customer support articles
The quality of the knowledge source strongly influences the quality of responses.
Retrieval Engine
The retrieval engine searches available content and identifies relevant information.
Its job is finding the right knowledge quickly.
Think of it as a highly efficient librarian.
Vector Database
Many RAG systems use vector databases to store and search information based on meaning rather than exact keywords.
This allows the system to understand concepts and context.
Popular vector databases include Pinecone, Weaviate, and Chroma.
Language Model
The language model generates the final response.
Models such as GPT, Claude, Gemini, and others are commonly used in RAG architectures.
RAG vs Traditional AI Models
At first glance, both systems appear similar.
The difference becomes obvious when answering knowledge-intensive questions.
Traditional AI
A traditional language model relies primarily on training data.
It cannot automatically access new information unless retrained or connected to external tools.
RAG-Powered AI
A RAG system retrieves information from external sources before generating an answer.
This makes responses:
- More current
- More context-aware
- Better grounded in real data
Think of traditional AI as memory-based.
Think of RAG as memory plus research.
Real-World Applications of RAG
RAG has quickly become one of the most widely adopted AI architectures.
Customer Support
Companies use RAG-powered chatbots to answer questions using support documentation and knowledge bases.
Customers receive faster and more accurate responses.
Enterprise Search
Employees can ask natural-language questions about internal policies, procedures, and documentation.
Instead of searching through folders, they simply ask.
Healthcare
Medical organizations use RAG systems to retrieve information from clinical guidelines, research papers, and healthcare documentation.
Human oversight remains critical, but information becomes easier to access.
Legal Research
Law firms use RAG systems to search large collections of legal documents and case law.
Research tasks that once took hours can be completed much faster.
Education
Students and educators use RAG-powered tools to access course materials, textbooks, and learning resources through conversational interfaces.
Why Businesses Love RAG
There are several reasons organizations are investing heavily in RAG systems.
Access to Current Information
Knowledge sources can be updated without retraining the entire AI model.
This keeps responses relevant.
Better Accuracy
Retrieved information provides factual grounding.
This often reduces incorrect or fabricated answers.
Company-Specific Knowledge
Businesses can connect internal documents and proprietary information.
The AI becomes familiar with the organization’s knowledge base.
Lower Costs
Retraining large AI models can be expensive.
RAG provides a practical alternative by retrieving information dynamically.
Challenges and Limitations
RAG is powerful, but it isn’t perfect.
Poor Data Leads to Poor Answers
If documents are outdated or inaccurate, the responses may suffer.
The quality of the knowledge source matters tremendously.
Retrieval Errors
Sometimes the system retrieves the wrong documents.
When that happens, response quality may decline.
Increased Complexity
A standard chatbot is relatively simple.
A RAG system introduces additional components, infrastructure, and maintenance requirements.
Security Concerns
Organizations must carefully manage access to sensitive information.
Strong permissions and governance become important.
Popular Technologies Used in RAG Systems
Many modern AI platforms support RAG architectures.
Common technologies include:
These tools help developers build retrieval systems, manage knowledge bases, and generate responses grounded in external data.
The Future of RAG
Many experts view RAG as one of the most practical approaches for enterprise AI.
As organizations collect larger volumes of information, the need for accurate retrieval becomes increasingly important.
Future RAG systems will likely:
- Search larger knowledge repositories
- Handle multiple data formats
- Retrieve information faster
- Support multimodal content
- Deliver more personalized responses
Rather than relying solely on what AI models remember, future systems will increasingly combine reasoning with real-time knowledge retrieval.
That’s where much of the industry’s attention is headed.
Final Thoughts
Retrieval-Augmented Generation is an AI architecture that combines external knowledge retrieval with generative AI. By retrieving relevant information before generating responses, RAG systems provide answers that are more accurate, current, and context-aware.
For businesses, educational institutions, healthcare providers, and technology companies, RAG offers a practical way to connect AI with real-world knowledge. As artificial intelligence continues to evolve, retrieval-based systems are expected to play a major role in making AI more reliable and useful.
Frequently Asked Questions (FAQs)
1. What does RAG stand for in AI?
RAG stands for Retrieval-Augmented Generation, an AI approach that retrieves information from external sources before generating responses.
2. Why is RAG important?
RAG helps AI provide more accurate and up-to-date answers by using external knowledge rather than relying solely on training data.
3. How does RAG differ from traditional AI models?
Traditional models answer questions from learned knowledge, while RAG systems retrieve relevant information before generating responses.
4. What types of data can a RAG system search?
RAG systems can search documents, PDFs, databases, websites, knowledge bases, research papers, and other information repositories.
5. Does RAG eliminate AI hallucinations?
No. RAG can reduce incorrect responses, but it cannot completely eliminate mistakes or misinformation.
6. Which industries use RAG?
RAG is widely used in customer support, healthcare, education, legal services, enterprise search, and knowledge management systems.