





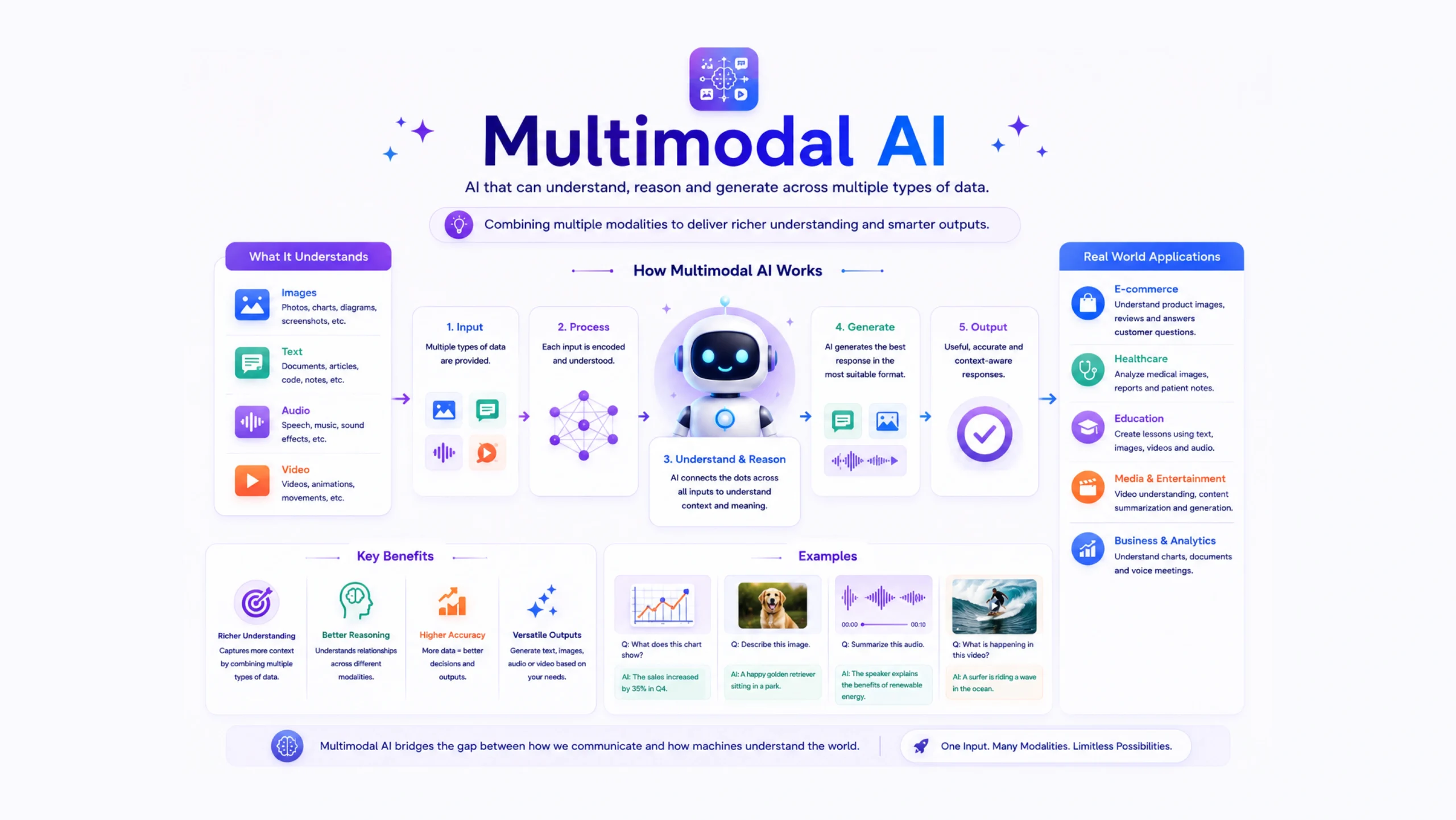
Multimodal AI refers to artificial intelligence systems that can work with multiple forms of information at the same time.
Traditional AI models often focus on a single type of data. A chatbot processes text. An image recognition system analyzes pictures. A speech assistant handles voice commands.
Multimodal AI combines these abilities.
It can understand text, images, audio, video, documents, and sometimes even sensor data within one system.
Imagine talking to an AI assistant, showing it a photo, uploading a PDF, and asking questions about both. The AI understands the relationship between all those inputs and responds accordingly.
That’s multimodal AI in action.
Why Multimodal AI Matters
Humans rarely communicate using a single format.
We speak, write, listen, observe, point at objects, watch videos, and interpret facial expressions. Information comes from many directions at once.
AI is gradually moving closer to this human-like way of processing information.
A system that understands both images and text can often provide richer answers than one that only understands text.
For example, if someone uploads a damaged product photo and asks, “Can this be repaired?” the AI can combine visual analysis with language understanding to provide a useful response.
The context becomes deeper and more meaningful.
A Simple Everyday Example
Think about ordering food online.
You read descriptions.
You view photos.
You check ratings.
You may even watch a short video review.
Your decision comes from multiple sources of information.
Multimodal AI follows a similar pattern. Instead of analyzing only one source, it combines several types of data to build a more complete picture.
How Does Multimodal AI Work?
At a high level, multimodal AI collects information from different inputs and converts them into formats the model can understand.
The system then connects these inputs and looks for relationships between them.
For example:
- A photo contains visual information.
- A voice recording contains audio information.
- A document contains textual information.
The model processes each input and combines them into a shared representation.
This allows the AI to reason across different formats instead of treating them as separate pieces of information.
The result is a response that reflects the entire context.
Understanding Modalities
The word “modality” simply refers to a type of data.
Common modalities include:
Text
Articles, emails, messages, reports, books, and documents.
Images
Photos, diagrams, screenshots, illustrations, and graphics.
Audio
Voice recordings, podcasts, music, and sound effects.
Video
Recorded footage, presentations, tutorials, and movies.
Sensor Data
Information collected from devices such as cameras, GPS systems, smart watches, or industrial equipment.
Modern multimodal systems can combine several of these inputs at once.
Real-World Examples of Multimodal AI
Multimodal AI is already becoming part of daily life.
AI Assistants
Modern assistants can understand text prompts, voice commands, images, and uploaded files.
A user might ask:
“What’s wrong with this plant?”
The AI examines the photo and combines visual recognition with language processing to answer.
Healthcare
Doctors can upload scans, patient notes, and medical records.
The AI can analyze multiple sources together and provide useful insights.
Education
Students can upload worksheets, screenshots, diagrams, and written questions.
The AI can explain concepts using the combined information.
Customer Support
Customers often submit screenshots, images, receipts, and written descriptions.
Multimodal systems can review everything at once rather than requiring separate tools.
Accessibility Tools
People with visual impairments can use AI systems that describe images, documents, and surroundings through spoken responses.
Why Businesses Are Paying Attention
Businesses generate information in many formats.
Support tickets contain text.
Marketing teams create images and videos.
Sales teams manage presentations.
Product teams collect screenshots and documents.
Analyzing all these assets separately creates friction.
Multimodal AI helps bring them together.
This can lead to faster decision-making and better productivity.
Benefits of Multimodal AI
The growing interest in multimodal systems isn’t surprising.
Several advantages make them appealing.
Better Context
Combining multiple data sources often produces a fuller picture of a situation.
Improved Accuracy
Information from one modality can support information from another.
More Natural Interactions
Humans naturally communicate through different channels.
Multimodal systems feel closer to real conversations.
Greater Flexibility
Users can provide information in the format that feels most convenient.
Richer Outputs
AI can generate text, images, summaries, captions, and explanations based on mixed inputs.
The Interesting Part: AI Starts Connecting Dots
Here’s where things get fascinating.
A text-only model sees words.
An image model sees pixels.
A multimodal model can connect the two.
It can identify objects in a picture and explain them in natural language.
It can watch a video and summarize key moments.
It can listen to audio and answer questions about what was said.
The AI begins linking information across formats rather than treating each one as a separate task.
Challenges and Limitations
Despite the excitement, multimodal AI still faces challenges.
Data Complexity
Different data types require different processing techniques.
Managing them together increases system complexity.
Higher Computing Requirements
Analyzing text, images, audio, and video simultaneously demands significant computational resources.
Privacy Concerns
Images, videos, and voice recordings may contain sensitive information.
Organizations must handle data responsibly.
Misinterpretation Risks
Mistakes can still happen.
A model may misunderstand an image, mishear audio, or misinterpret context.
Human oversight remains valuable.
Multimodal AI vs Traditional AI
The distinction is fairly simple.
Traditional AI
Works primarily with one type of input.
Examples:
- Text-only chatbots
- Speech recognition tools
- Image classification systems
Multimodal AI
Works with multiple input types simultaneously.
Examples:
- AI assistants that analyze photos and text together
- Systems that summarize videos and answer questions
- Applications that combine speech, images, and documents
The difference is similar to comparing a specialist with a generalist.
Each has strengths, but multimodal systems can handle a broader range of situations.
Industries Being Changed by Multimodal AI
Many sectors are already exploring multimodal capabilities.
Healthcare
Medical imaging, patient records, and doctor notes can be analyzed together.
Education
Students receive support using text, diagrams, and visual learning materials.
Retail
AI can analyze product images, descriptions, and customer reviews.
Manufacturing
Systems can combine machine sensor data, images, and maintenance records.
Media and Content Creation
Creators can generate videos, images, captions, scripts, and summaries using a single workflow.
What the Future Looks Like
AI is steadily moving toward systems that understand information more like humans do.
Future multimodal systems may:
- Understand complex visual scenes
- Analyze live video streams
- Interpret emotional tone in speech
- Work with real-time environmental data
- Combine dozens of information sources simultaneously
The goal isn’t simply processing more data.
The goal is connecting information in meaningful ways.
Final Thoughts
Multimodal AI is a type of artificial intelligence that can understand and generate multiple forms of data, including text, images, audio, video, and documents. By combining these inputs, it gains a broader view of a situation and can provide richer, more context-aware responses.
From healthcare and education to customer support and content creation, multimodal AI is changing how people interact with technology. As AI systems continue to evolve, the ability to work across multiple data types is likely to become a standard feature rather than a specialized capability.
Frequently Asked Questions (FAQs)
1. What is multimodal AI?
Multimodal AI is an AI system that can process and understand multiple types of data, such as text, images, audio, video, and documents.
2. How is multimodal AI different from traditional AI?
Traditional AI usually focuses on a single type of data, while multimodal AI combines several data formats within one system.
3. What are examples of multimodal AI?
Examples include AI assistants that analyze photos and text together, video summarization tools, and systems that process documents alongside images.
4. Why is multimodal AI important?
It provides richer context, improves understanding, and creates more natural interactions between humans and machines.
5. Can multimodal AI generate content?
Yes. Many multimodal systems can generate text, images, captions, summaries, and other forms of content based on mixed inputs.
6. What industries use multimodal AI?
Healthcare, education, retail, manufacturing, customer support, media, and many other industries are actively using or exploring multimodal AI solutions.